Exkurs - Shift-Reduce-Parser
Ein Kellerautomat zur Simulation einer Rechtsableitung
Wir betrachten weiterhin die Sprache LRA der vereinfachten Rechenausdrücke mit
der Grammatik G:
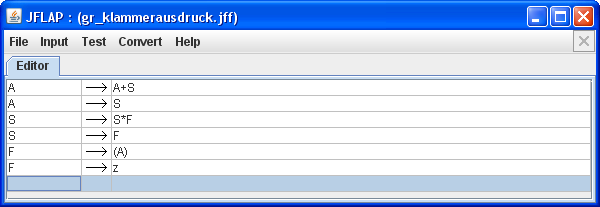
A -> A+S A -> S S -> S*F S -> F F -> (A) F -> z
Die Grammatik G geben wir in JFlap ein:
Mit den Menupunkten [Convert][Convert CFG to PDA (LR)] lässt sich jetzt ein Kellerautomaten erzeugen:
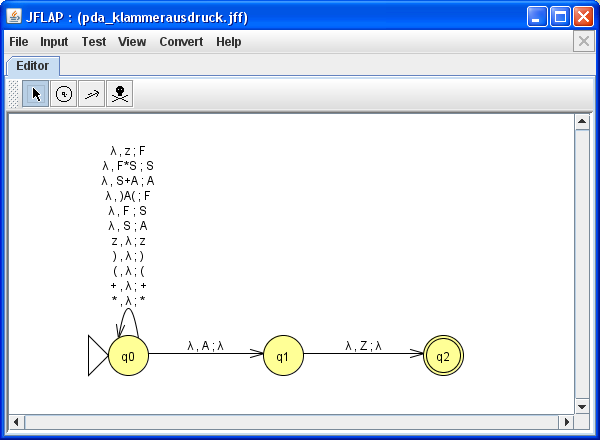
Mit [Export] kann man den erzeugten Kellerautomaten in ein neues Fenster kopieren.
Wie der erzeugte Kellerautomat arbeitet, soll anhand des Eingabeworts z+z*(z+z)
verdeutlicht werden.
Mit
[Input][Fast Run] lässt sich eine Ableitung zu einem Eingabewort (hier z+z*(z+z))
erzeugen.
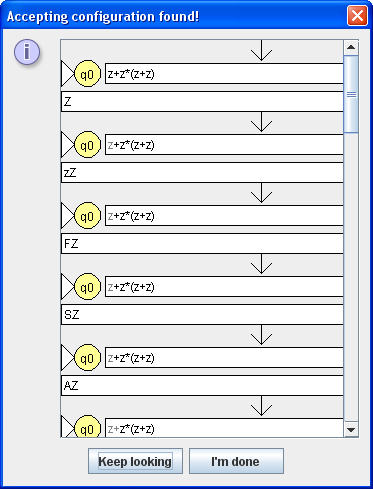
Die folgende Übersicht gibt die gesamte Ableitung wieder. Eingetragen sind hier der jeweilige Zustand, der aktuelle Kellerinhalt und das verbleibende Eingabewort. Zusätzlich sind die benutzten Zustandsübergänge angegeben sowie eine Kommentierung der Übergänge.
Zustand; Kellerinhalt Eingabewort Aktion =================================================================== q0; Z z+z*(z+z)$ | z,λ;z shift z q0; zZ +z*(z+z)$ | λ,z;F reduce by F->z q0; FZ +z*(z+z)$ | λ,F;S reduce by S->F q0; TZ +z*(z+z)$ | λ,S;A reduce by A->S q0; SZ +z*(z+z)$ | +,λ;+ shift + q0; +AZ z*(z+z)$ | z,λ;z shift z q0; z+AZ *(z+z)$ | λ,z;F reduce by F->z q0; F+AZ *(z+z)$ | λ,F;S reduce by S->F q0; S+AZ *(z+z)$ | *,λ;* shift * q0; *S+AZ (z+z)$ | (,λ;( shift ( q0; (*S+AZ z+z)$ | z,λ;z shift z q0; z(*S+AZ +z)$ | λ,z;F reduce by F->z q0; F(*S+AZ +z)$ | λ,F;S reduce by S->F q0; S(*S+AZ +z)$ | λ,S;A reduce by A->S q0; A(*S+AZ +z)$ | +,λ;+ shift + q0; +A(*S+AZ z)$ | z,λ;z shift z q0; z+A(*S+AZ )$ | λ,z;F reduce by F->z q0; F+A(*S+AZ )$ | λ,F;S reduce by S->F q0; S+A(*S+AZ )$ | λ,S+A;A reduce by A->A+S q0; A(*S+AZ )$ | ),λ;) shift ) q0; )A(*S+AZ $ | λ,)A(;F reduce by F->(A) q0; F*S+AZ $ | λ,F*S;S reduce by S->S*F q0; S+AZ $ | λ,S+A;A reduce by A->A+S q0; AZ $ | λ,A;λ q1; Z $ | λ,Z;λ q2 $
Es fällt auf, dass alle wesentlichen Aktionen im Zustand q0 ausgeführt werden.
Der Keller wird hier benutzt, um eine Ableitung des Eingabeworts z+z*(z+z) mit
den Grammatikregeln aus G zu simulieren - allerdings auf eine im ersten Moment
schwer zu durchschauende Weise.
Verständlich wird sie, wenn man sich die folgende Ableitung des Worts z+z*(z+z) mit
den Grammatikregeln aus G genauer anschaut.
A reduce by A -> A+S -> A+S reduce by S -> S*F -> A+S*F reduce by F -> (A) -> A+S*(A) reduce by A -> A+S -> A+S*(A+S) reduce by S -> F -> A+S*(A+F) reduce by F -> z -> A+S*(A+z) reduce by A -> S -> A+S*(S+z) reduce by S -> F -> A+S*(F+z) reduce by F -> z -> A+S*(z+z) reduce by S -> F -> A+F*(z+z) reduce by F -> z -> A+z*(z+z) reduce by A -> S -> S+z*(z+z) reduce by S -> F -> F+z*(z+z) reduce by F -> z -> z+z*(z+z)
Die gezeigte Ableitung ist eine sogenannte Rechtsableitung. In jedem Ableitungsschritt wird das am
weitesten rechts stehende Nichtterminalsymbol mit einer Regel aus G ersetzt.
Wenn man die Ableitung von unten nach oben liest, dann sieht man Zusammenhänge zu den Zustandsübergängen
des Kellerautomaten.
Kellerinhalt Eingabewort Aktion ============================================================== Z z+z*(z+z)$ shift z zZ +z*(z+z)$ reduce by F -> z FZ +z*(z+z)$ reduce by S -> F SZ +z*(z+z)$ reduce by A -> S AZ +z*(z+z)$ shift + +AZ z*(z+z)$ shift z z+AZ *(z+z)$ reduce by F -> z F+AZ *(z+z)$ reduce by S -> F S+AZ *(z+z)$ shift * *S+AZ (z+z)$ shift ( (*S+AZ z+z)$ shift z z(*S+AZ +z)$ reduce by F -> z F(*S+AZ +z)$ reduce by S -> F S(*S+AZ +z)$ reduce by A -> S A(*S+AZ +z)$ shift + +A(*S+AZ z)$ shift z z+A(*S+AZ )$ reduce by F -> z F+A(*S+AZ )$ reduce by S -> F S+A(*S+AZ )$ reduce by A -> A+S A(*S+AZ )$ shift ) )A(*S+AZ $ reduce by F -> (A) F*S+AZ $ reduce by S -> S*F S+AZ $ reduce by A -> A+S AZ $
Der Keller ist zu Beginn leer.
Nach und nach werden mit sogenannten shift-Aktionen Symbole des
Eingabeworts im Keller abgelegt.
Wenn möglich, wird dann mit einer sogenannten reduce-Aktion eine
Produktion rückwärts angewandt.
Beachte auch, dass rechte Seiten von Produktionen im Keller in umgekehrter Reihenfolge
dargestellt werden.
Als nachteilig erweisen sich beim gezeigten Kellerautomaten die vielen nichtdeterministischen Zustandsübergänge.
Wenn man mit [Input][Step by State] ein Eingabewort wie z.B. z+z*(z+z) schrittweise
analysiert, dann ergibt sich schnell eine Vielzahl von möglichen Ableitungen.
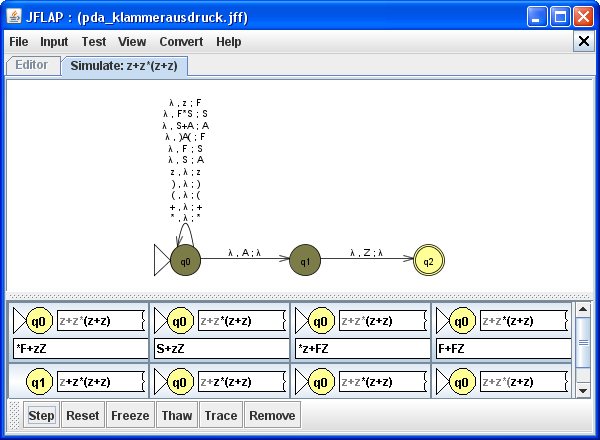
Eine effiziente Nutzung des Kellerautomaten erfordert eine Strategie, nach der man die jeweiligen Zustandsübergänge (bzw. Aktionen) auswählt. Am besten wäre hier eine Strategie, die eine deterministische Vorgehensweise ermöglichen würde.
Steuerung von Aktionen mit einer Parsingtabelle
Eine solche Strategie gibt es tatsächlich für viele kontextfreie Grammatiken.
Wir starten wieder mit der der Grammatik G für die Sprache LRA
der vereinfachten Rechenausdrücke.
JFlap erzeugt mit [Input][Build SLR(1) Parse Table][Do All] eine sogenannte Parsingtabelle.
Mit [Parse] kann man dann ein Eingabewort wie z.B. z+z*(z+z) schrittweise
analysieren.
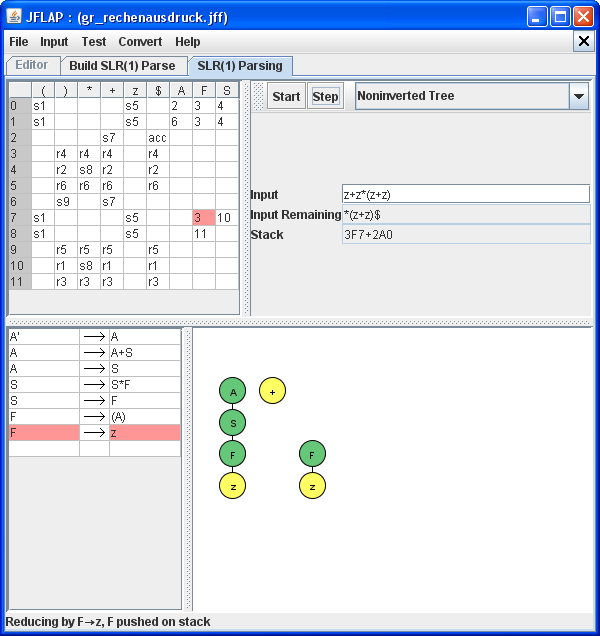
Der Parsing-Vorgang mit JFlap verdeutlicht auf sehr anschauliche Weise die oben beschriebene bottom-up-Rückwärtsableitung des Eingabeworts. Zur Steuerung der Aktionen wird die erzeugte Parsingtabelle benutzt. Diese soll jetzt genauer betrachtet werden.
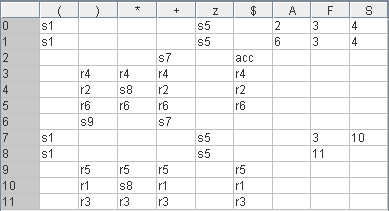
Der Parsingtabelle benutzt Zustände zur Steuerung von Aktionen. Diese sind als Nummmern (von 0 bis 11)
in der linken Spalte aufgeführt.
In der obersten Zeile sind die Terminal- und Nichtterminalsymbole aufgelistet.
Unterhalb der Terminalsymbole findet man Einträge der Gestalt s... (für shift-Aktionen) und
r... (für reduce-Aktionen) sowie acc (für eine accept-Aktion).
Die leeren Einträge sind als rej (für eine reject-Aktion) zu interpretieren.
Unterhalb der Nichtterminalsymbole findet man als Einträge nur Nummern. Diese stehen für
Übergänge in neue Zustände.
Beachte, dass die Parsingtabelle sich auf die Produktionen der vorgegebenen Grammatik bezieht.
Die Produktionen werden hierzu durchnummeriert und geringfügig erweitert.
Zur Steuerung der Vorgänge bei einer bottom-up-Rückwärtsableitung des Eingabeworts wird der folgende - auf der Parsingtabelle basierende - Algorithmus benutzt.
ALGORITHMUS shift-reduce-Analyse
lege 0 im Stapel ab
WIEDERHOLE
zustand = oberstes Symbol im Stapel
lookahead = erstes Zeichen im aktuellen Eingabewort
aktion = Eintrag in der Parsingtabelle zum Paar (zustand, lookahead)
FALLS aktion == shift i (kurz: si):
entferne das erste Zeichen des Eingabeworts und ...
... lege es im Stapel ab
lege i im Stapel ab
FALLS aktion == reduce i (kurz: ri):
entferne doppelt so viele Symbole vom Stapel, ...
... wie Symbole auf der rechten Seite von Produktion i stehen
zustand = oberstes Symbol vom Stapel
symbol = linke Seite von Produktion i
zustand = Eintrag in der Parsingtabelle zum Paar (zustand, symbol)
lege symbol im Stapel ab
lege zustand im Stapel ab
BIS aktion == acc oder aktion == rej (bzw. leerer Eintrag)
Die Arbeitsweise des Algorithmus soll am Beispiel verdeutlicht werden.
Wir beginnen mit dem Kellerinhalt / Stapelinhalt 0
und dem Eingabewort z+z*(z+z)$. Beachte, dass das zu verarbeitende Eingabewort z+z*(z+z) um ein Zeichen zur
Markierung des Wortendes erweitert wurde.
Der aktuelle Zustand ist das oberste Stapelelement, also 0. Das erste Zeichen des Eingabeworts
ist das Zeichen z. In der Parsingtabelle kann man die nächste Aktion ablesen,
in der vorliegenden Situation ist es die Aktion s5.
0; z+z*(z+z)$ | s5 shift z 5z0; +z*(z+z)$
Die Aktion s5 entfernt das erste Zeichen des Eingabeworts z+z*(z+z)$. Es verbleibt
das Eingabewort +z*(z+z)$. Das entfernte Zeichen und die in der shift-Aktion angegebene Nummer
werden auf den Stapel gelegt. Der neue Stapelinhalt ist jetzt 5z0. Das Verarbeitungssystem
befindet sich also im Zustand 5.
Aus dem aktuellen Zustand 5 und dem ersten Zeichen des verbleibenden Eingabeworts +
ergibt sich aus der Parsingtabelle die nächste auszuführende Aktion r6.
5z0; +z*(z+z)$ | r6 reduce by F->z 3F0; +z*(z+z)$
Die Aktion r6 bedeutet hier reduce by F->z
, da der Produktion F -> z
die Nummer 6 zugeordnet ist.
Zuerst werden doppelt soviele Elemente vom Stapel entfernt, wie Symbole auf
der rechten Seite von Produktion 6 stehen. Der Stapelinhalt ist dann 0.
Das oberste Stapelelement legt den aktuellen Zustand fest. Das ist hier der Zustand 0.
In der Parsingtabelle wird jetzt der neue Zustand ermittelt. Man erhält ihn,
indem man den Eintrag zum aktuellen Zustand und der linken Seite der zu verarbeitenden Produktion
nachschlägt. In der aktuellen Situation Zustand: 0; linke Seite der Produktion: F
erhält
man Zustand 3.
Abschließend werden die linke Seite der Produktion F und der neue Zustand 3
auf den Stapel gelegt.
Ziemlich kompliziert, oder? Hier der gesamte Analysevorgang.
Kellerinhalt; Eingabewort Aktion ============================================================== 0; z+z*(z+z)$ | s5 shift z 5z0; +z*(z+z)$ | r6 reduce by F->z 3F0; +z*(z+z)$ | r4 reduce by S->F 4S0; +z*(z+z)$ | r2 reduce by A->S 2A0; +z*(z+z)$ | s7 shift + 7+2A0 z*(z+z)$ | s5 shift z 5z7+2A0 *(z+z)$ | r6 reduce by F->z 3F7+2A0 *(z+z)$ | r4 reduce by S->F 10S7+2A0 *(z+z)$ | s8 shift * 8*10S7+2A0 (z+z)$ | s1 shift ( 1(8*10S7+2A0 z+z)$ | s5 shift z 5z1(8*10S7+2A0 +z)$ | r6 reduce by F->z 3F1(8*10S7+2A0 +z)$ | r4 reduce by S->F 4S1(8*10S7+2A0 +z)$ | r2 reduce by A->S 6A1(8*10S7+2A0 +z)$ | s7 shift + 7+6A1(8*10S7+2A0 z)$ | s5 shift z 5z7+6A1(8*10S7+2A0 )$ | r6 reduce by F->z 3F7+6A1(8*10S7+2A0 )$ | r4 reduce by S->F 10S7+6A1(8*10S7+2A0 )$ | r1 reduce by A->A+Z 6A1(8*10S7+2A0 )$ | s9 shift ) 9)6A1(8*10S7+2A0 $ | r5 reduce by F->(A) 8*10S7+2A0 $ | r3 reduce by S->S*F 10S7+2A0 $ | r1 reduce by A->A+S 2A0 $ | acc accept A0 $
Die vorliegende Parsingtabelle zur Grammatik G macht den Analysevorgang bei beliebigen Eingabewörtern
deterministisch. Sie bildet also den Schlüssel zum effizienten Lösen des Wortproblems.
Nur, wie gewinnt man die Parsingtabelle? JFlap zeigt, wie das geht. Der Algorithmus zur Erzeugung einer Parsingtabelle aus einer kontextfreien Grammatik ist recht kompliziert und soll hier nicht weiter betrachtet werden. Der Algorithmus wird in der Regel nicht von Hand ausgeführt, sondern von geeigneten Werkzeugen (wie JFlap). Werkzeuge, die Parsingtabellen erzeugen und zur Wortanalyse nutzen können, nennt man auch Parser-Generatoren. Beachte, dass Parser-Generatoren nicht aus jeder kontextfreien Grammatik eine deterministische Parsingtabelle erzeugen können.
Zusammenfassung
Viele Sprachen, die in der Praxis genutzt werden, können durch kontextfreie Grammatiken beschrieben werden. Automatisiert erzeugte Kellerautomaten zur Erkennung solcher Sprachen sind meist nichtdeterministisch und daher zum praktischen Einsatz wenig geeignet.
Zum Erkennen kontextfreier Sprachen nutzt man in der Praxis Shift-Reduce-Parser mit geeigneten Parsingtabellen. Solche Shift-Reduce-Parser benutzen - genau wie Kellerautomaten - einen Keller / Stapel zum Zwischenspeichern von Symbolen. Anders als Kellerautomaten nutzen sie aber eine Art Vorschau auf das nächste zu verarbeitende Eingabesymbol.
Shift-Reduce-Parser arbeiten deterministisch, d.h. sie können Wortprobleme direkt - ohne Ausprobieren mehrerer Möglichkeiten - lösen. Man kann jedoch nicht zu jeder kontextfreien Grammatik einen passenden Shift-Reduce-Parser automatisiert erzeugen. Nur wenn die Grammatik eine bestimmte Gestalt hat, ist eine automatisierte Erzeugung möglich.
Verfahren zur Erzeugung von Shift-Reduce-Parsern sind komplex und werden daher hier nicht behandelt.
