Ziffernerkennung
In diesem Kapitel soll eine künstliches neuronales Netz zur Bilderkennung trainiert werden. Als Trainigsdatensatz verwenden wir den sogenannten MNIST-Datensatz (Modified National Institute of Standards). Dieser Datensatz enthält 70.000 Bilder von handgeschriebenen Ziffern und wird weltweit als Standarddatensatz für Bilderkennungsverfahren verwendet.
 Die einzelnen Bilder liegen als Grauwertbilder mit einer Auflösung von 28 x 28 Pixeln vor.
Die einzelnen Bilder liegen als Grauwertbilder mit einer Auflösung von 28 x 28 Pixeln vor.
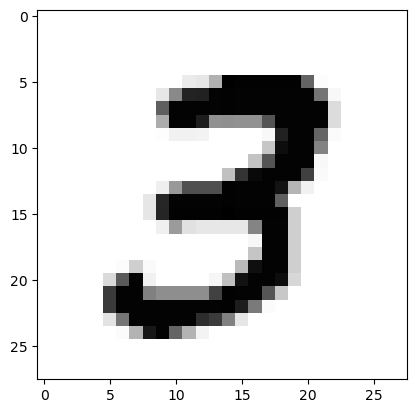
Jedes Bild besteht also aus $28 \cdot 28 = 784$ Grauwert-Pixeln und soll klassifiziert werden als eine der Ziffern ${0, ... ,10}$. Daher verwenden wir ein KNN mit 784 Eingangs- und 10 Ausgangs-Neuronen. Um das KNN übersichtlich zu halten, wählen wir zunächst "nur" ein einziges Hidden-Layer mit 50 künstlichen Neuronen.
Allerdings ist selbst dieses relativ "übersichtliche" KNN schon etwas schwer zu zeichnen. Um einen visuellen Eindruck von der Datenmenge zu bekommen, zeichnen wir stattdessen beispielhaft einfach einmal ein deutlich kleineres KNN mit nur 70 Eingangs-, 50 Hidden-Layer- und 10 Output-Neuronen:

Aufgabe 1
Berechne, wie viele Gewichte und Biases unser KNN mit 784 Input-, 50 Hidden-Layer- und 10 Output-Neuronen insgesamt besitzt.
Zum Abspeichern dieser Werte werden wir im Folgenden den Python-Datentyp float verwenden. Recherchiere, welche Größe dieser Datentyp hat und berechne, welche Datenmenge daher insgesamt zum Abspeichern der Gewichte und der Biases anfällt.
Hinweis

